



Table of contents
This blog exclusively covers the options available in AWS to recover SAP HANA Database with low cost and without using native HSR tool of SAP. With a focus on low costs, Sify recommends choosing a cloud native solution leveraging EC2 Auto Scaling and AWS EBS snapshots that are not feasible in an on-premises setup.
Solution Overview
The Restore process leveraging Auto Scaling and EBS snapshots works across availability zones in a region. Snapshots provide a fast backup process, independent of the database size. They are stored in Amazon S3 and replicated across Availability Zones automatically, meaning we can create a new volume out of a snapshot in another Availability Zone. In addition, Amazon EBS snapshots are incremental by default and only the delta changes are stored since the last snapshot. To create a resilient highly available architecture, automation is key. All steps to recover the database must be automated in case something fails or goes wrong.
Autoscaling Architecture
The following diagram shows the Auto Scaling architecture for systems in AWS.
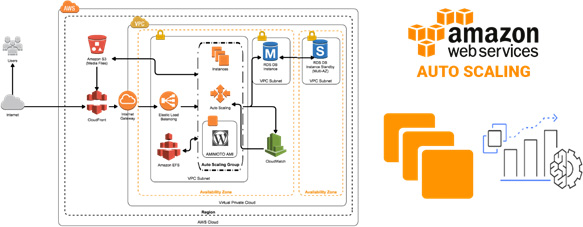
Use Case
EBS Snapshots
Prior to enabling EBS snapshots we must ensure the destination of log backups are written to an EFS folder which is available across Availability Zones.
Create a script prior to the command to be executed for an EBS snapshot. By using the system username and password, we make an entry into the HANA backup catalog to ensure that the database is aware of the snapshot backup. We use the snapshot feature to take a point in time and crash consistent snapshot across multiple EBS volumes without a manual I/O freeze. It is recommended to take the snapshot every 8-12 hours.
Now the log backups are stored in EFS and full backups as EBS snapshots in S3 and both sets are available across AZs. Both storage locations can be accessed across AZs in a region and are independent of an AZ.
EC2 Auto Scaling
Next, we create an Auto Scaling group with a minimum and maximum of one instance. In case of an issue with the instance, the Auto Scaling group will create an alternative instance out of the same AMI as the original instance.
We first create a golden AMI for the Auto Scaling group and the AMI is used in a launch configuration with the desired instance type. With a shell script in the user data, upon launch of the instance, new volumes are created out of the latest EBS snapshot and attached to the instance. We can use the EBS fast snapshot restore feature to reduce the initialization time of the newly created volumes.
If the database is started now (recently), it would have a crash consistent state. In order to restore it to the latest state, we can leverage the log backup stored in EFS which is automatically mounted by the AMI. Additional Care to be taken so that the SAP application server is aware of the new IP of the restored SAP HANA database server.
Benefits
- Better fault tolerance – Amazon EC2 Auto Scaling can detect when an instance is unhealthy, terminate it, and launch an instance to replace it. Amazon EC2 Auto Scaling can also be configured to use multiple Availability Zones. If one Availability Zone becomes unavailable, Amazon EC2 Auto Scaling can launch instances in another one to compensate.
- Better availability – Amazon EC2 Auto Scaling helps in ensuring the application always has the right capacity to handle the current traffic demand.
- Better cost management – Amazon EC2 Auto Scaling can dynamically increase and decrease capacity, as needed. Since AWS has pay for the EC2 instances, billing model can be used to save money, by launching instances only when they are needed and terminating them when they aren’t.
Conclusion
This blog discussed how Sify can help SAP customers to save cost by automating recovery process for HANA database, using native AWS tools. Sify would be glad to help your organization as your AWS Managed Services Partner for a tailor-made SAP on AWS Cloud solution involving seamless cloud migration experience and for your Cloud Infrastructure management thereafter.











")








")








")
")
 framework for software and product development.")
")
 standard specifically designed for the telecommunications industry")

 in public cloud environments")












