



Table of contents
Introduction
Consider these scenarios:
- A checkout page that takes a second too long to respond.
- A video call that freezes during an important discussion.
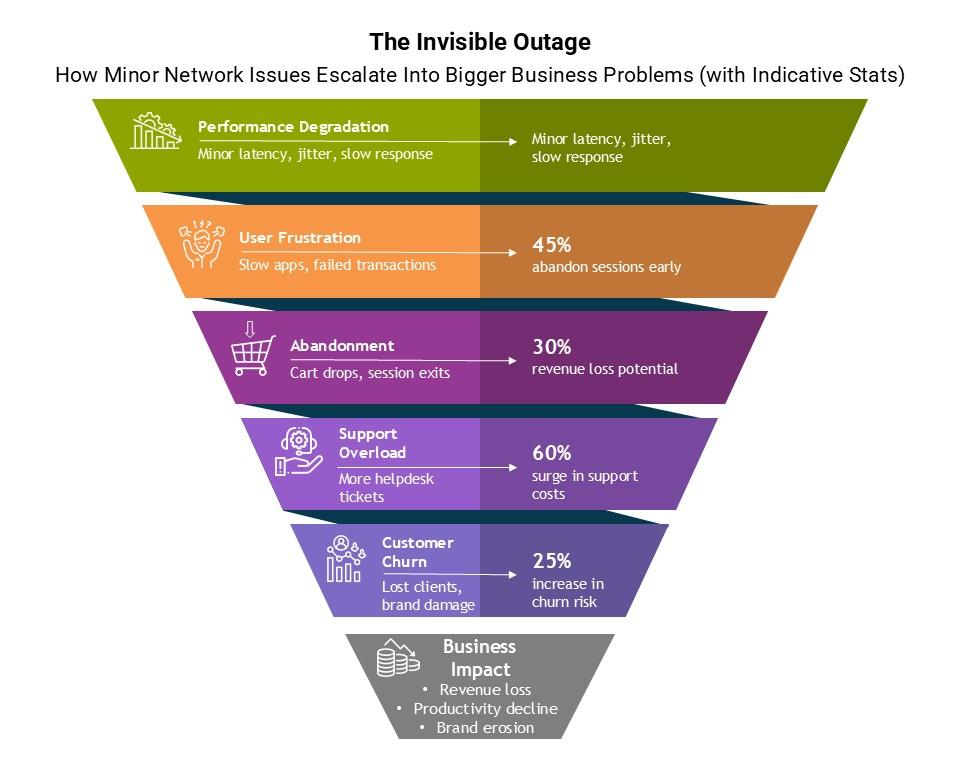
These moments rarely show up as full-scale outages, yet they shape how customers and employees experience the business. In most cases, nothing has “failed” outright. The network is still running. Systems are technically available. And yet, performance has slipped just enough to matter.
This is the reality of modern enterprise networks. They are no longer static environments with hardcoded data routing and predictable traffic patterns. The network itself has become a disparate system of networks with varying architectures to support different business needs. They span on-prem data centers, multiple clouds, SaaS platforms, remote users, and increasingly, AI-driven workloads. In such environments, outages are often the final outcome of small, seemingly unrelated issues occurring across different parts of the network – issues that go unnoticed because their correlation is not visible in real time. Only after a failure, during root-cause analysis, do these relationships become clear.
AI network monitoring exists to address this exact gap.
Why traditional network monitoring no longer keeps up
Most enterprises already monitor their networks. Dashboards track utilization. Alerts trigger when thresholds are crossed. Logs are collected in vast quantities.
Despite this, performance issues and service disruptions persist.
The issue is not a lack of visibility. It is a lack of understanding, especially at a speed where incidents can be prevented.
Traditional monitoring systems depend heavily on static thresholds and isolated metrics. A spike in latency or CPU usage may trigger an alert, but it offers little insight into whether the issue is transient, systemic, or likely to escalate. In highly dynamic environments, what looks abnormal at one moment may be perfectly normal at another.
As networks grow more distributed and interdependent, static rules age quickly. Teams end up reacting to alerts after users are already affected, spending valuable time correlating data across tools to understand what actually happened.
This reactive posture is increasingly misaligned with how modern networks behave.
The business cost of network blind spots
Network issues are often framed as technical inconveniences, but their impact extends well beyond IT.
Even brief performance degradation can slow transactions, disrupt customer journeys, and reduce employee productivity. In customer-facing systems, as in the case of trading applications, milliseconds matter. Internally, repeated slowdowns translate into support tickets, lost time, and frustration across teams.
What makes this especially challenging is that many incidents never register as “critical.” The network does not go down. Applications do not crash. Yet the experience deteriorates enough to affect outcomes. By the time the issue is formally escalated, the opportunity to circumvent impact has already passed.
Notably, network resilience and flexibility are increasingly becoming boardroom discussions than isolated technical discussions as enterprises mature in their digital transformation curves.
From monitoring to observability: an essential shift
Routine monitoring tasks address a narrow question: is something wrong right now?
Observability goes further by asking why it is happening and what is likely to happen next.
In an observability-driven approach, metrics, logs, flow data, and events are analyzed together rather than in isolation. Relationships between applications, network paths, and infrastructure are continuously mapped, allowing teams to see how changes in one area ripple across the system.
This matters because modern outages are rarely caused by a single failure. They emerge from interactions between systems that were never designed to operate in isolation. Intelligent observability helps teams understand these interactions and pinpoint root causes faster, without relying on guesswork or manual correlation.
In practice, this shift increasingly points toward full-stack observability – where network telemetry is correlated with application behavior, infrastructure performance, cloud resources, and security signals in a single, coherent view. By breaking down silos between layers, full-stack observability helps teams understand not just where an issue surfaced, but how it originated and propagated across the stack, making faster and more accurate diagnosis possible in real time.
What AI network monitoring does differently
AI network monitoring shifts the focus from reacting to individual alerts to understanding behavior over time.
Instead of relying on predefined thresholds, AI-driven systems continuously learn what normal looks like across the network. They analyze traffic patterns, latency trends, and interactions between network paths, applications, and infrastructure components. From this, they build dynamic baselines that adapt as the environment evolves.
When behavior deviates from these baselines, the system evaluates the deviation in context. A short spike may be ignored. A subtle but persistent pattern may be flagged as early risk. The emphasis is not on alerting more often, but on alerting more intelligently.
This is how teams move from firefighting incidents to anticipating them.
| Aspect | Traditional monitoring | AI-driven observability |
|---|---|---|
| Primary focus | Device and link health | End-to-end system behavior |
| Data handling | Metrics and alerts in silos | Metrics, logs, flows, and events correlated |
| Detection model | Static thresholds | Behavioral baselines and anomaly detection |
| Insight timing | After degradation occurs | Early warning before impact |
| Root-cause analysis | Manual, post-incident | Automated, real-time correlation |
| Business impact view | Limited | Tied to application and user experience |
| Operating model | Reactive troubleshooting | Predictive, intent-driven assurance |
Staying ahead of outages with predictive intelligence
According to Gartner, AI-optimized infrastructure is emerging as the next major growth engine for AI adoption, with end-user spending expected to reach $37.5 billion by 2026 as enterprises scale beyond experimentation.
One of the most valuable outcomes of AI-enabled network monitoring is early warning.
By analyzing historical trends alongside real-time behavior, AI models can identify patterns that typically precede degradation. Gradual increases in latency, recurring congestion during specific workloads, or subtle shifts in traffic distribution can all signal future risk.
Instead of waiting for performance to degrade, teams gain time to act. Capacity can be adjusted, routes optimized, or configurations corrected before users notice any impact.
This shift from reacting to incidents to preventing them fundamentally changes how network operations teams work.
Early warning capabilities are also setting the stage for more autonomous, agentic operations. As AI models mature, network monitoring begins to evolve from insight generation to guided action, where systems not only surface risks, but recommend or initiate corrective steps with minimal human intervention.
This shift is reshaping the traditional network operations center into a quieter, “dark NOC” model, where teams oversee intent, policy, and exceptions rather than manually responding to every alert. The result is not less control, but more leverage – freeing engineers to focus on optimization and innovation instead of constant incident response.
Why AI workloads raise the stakes even higher
As enterprises scale AI and data-intensive applications, the tolerance for network inefficiency drops to near zero. Unlike traditional enterprise systems, AI workloads are highly sensitive to latency variation, packet loss, and throughput instability – even when infrastructure appears healthy on the surface.
Consider a common enterprise scenario: a distributed model training pipeline running across multiple clusters or cloud regions. Data must move continuously between storage, compute, and accelerators, creating sustained east–west traffic inside the network. A slight increase in congestion or jitter may not trigger a conventional alert, yet it can slow training cycles, extend time to insight, and drive up compute costs. In inference-heavy environments, the same conditions can introduce response-time variability that directly affects customer-facing applications.
This is where many organizations encounter blind spots. Traditional monitoring may show links, interfaces, and devices operating within acceptable thresholds, while performance bottlenecks quietly emerge at the interaction layer – where traffic patterns, routing decisions, and workload behavior intersect. The result is not always downtime, but inconsistent AI performance that is difficult to trace back to the network.
For CIOs and CTOs, this shifts the question from availability to assurance.
Intelligent observability becomes critical not just to keep systems running, but to ensure predictable performance, cost efficiency, and reliable AI outcomes. When AI is central to business strategy, the network can no longer be treated as passive infrastructure. It becomes an active, continuously optimized foundation for competitive advantage.
Building an intelligent digital foundation with Sify
To truly stay ahead of outages, enterprises need more than standalone monitoring tools. They need an AI-ready digital foundation where intelligence is embedded across networks, data centers, cloud platforms, security, and operations.
This is where Sify plays a strategic role.
With two decades of experience supporting enterprise digital infrastructure, Sify approaches AI network monitoring as part of a broader effort to enable resilient, future-ready operations. We pioneered India’s first and largest MPLS network by connections – 3,700+ PoPs across 1,600 towns. We’re implementing and managing business-critical, complex networks of national importance for 700+ enterprises.
By combining intelligent networks, scalable AI-ready data centers, cloud-agnostic platforms, integrated security, and full-stack managed services, Sify helps enterprises turn observability into operational advantage.
Rather than treating outages as inevitable events to manage, this approach focuses on prevention, resilience, and continuous assurance – ensuring that the network evolves in step with business and AI ambitions.
From reacting to outages to engineering resilience
Outages may never disappear entirely, but their impact can be dramatically reduced.
AI network monitoring enables enterprises to see problems earlier, understand systems more deeply, and act before users are affected. It transforms networks from opaque, reactive systems into intelligent, observable environments that adapt alongside the business.
For organizations navigating hybrid IT, rising customer expectations, and the growing demands of AI workloads, intelligent observability is no longer optional. It is becoming a core capability for staying resilient, competitive, and ahead of disruption. Connect with us to get started on this journey.





")















")








")
")
 framework for software and product development.")
")
 standard specifically designed for the telecommunications industry")

 in public cloud environments")






